How Reliable Is LLM Brand Citation Tracking? An Honest Review
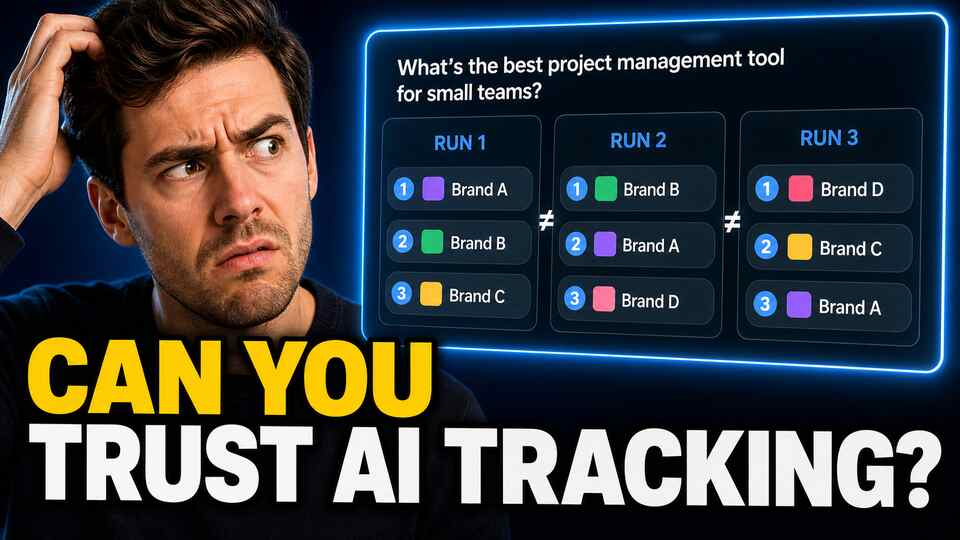
You asked ChatGPT which tools are best in your category. Your brand showed up. You ran the same prompt five minutes later. It didn't. You tried a third time. Different answer again. Now you're wondering whether tracking brand mentions in AI responses is even possible, or whether you're just measuring noise.
This is the right question to be asking. LLM brand citation tracking is real and useful, but only if the methodology is designed around a fundamental property of how large language models work: they are non-deterministic. Ignoring this makes any monitoring data meaningless. Accounting for it correctly makes the data genuinely valuable.
Why LLMs Give Different Answers to the Same Prompt
Large language models don't retrieve information from a database the way a search engine does. They generate responses probabilistically. Each token in the response is sampled from a distribution of possible next tokens, influenced by a temperature parameter that controls how much randomness is introduced.
In practical terms, this means the same prompt can produce meaningfully different outputs each time you run it. Run "what are the best project management tools for remote teams?" ten times and you might get ten slightly different lists. Sometimes your brand appears in position two. Sometimes it doesn't appear at all. Sometimes a competitor gets described differently.
This isn't a bug. It's how these models are designed to work. It becomes a serious problem for monitoring when tools treat a single response as ground truth.
What Unreliable Monitoring Looks Like
The worst approach: send a prompt once, record whether your brand appeared, report that as your "citation status." This is what a lot of simpler tools do.
The problem is obvious once you understand non-determinism. A single run might show your brand mentioned when you have a 30% citation rate on that prompt. It might also show your brand missing when your rate is actually 70%. Either way, the single data point tells you almost nothing about your true visibility.
This gets compounded when you're only monitoring a handful of prompts. Your brand might appear in response to one prompt your tool tracks but be completely absent from the 50 higher-intent prompts that actually drive buyer decisions. A narrow prompt set + single-run sampling = a monitoring setup that makes you feel informed while leaving you blind.
It also gets worse across engines. ChatGPT, Gemini, Grok, and Perplexity each have different training data, retrieval mechanisms, and temperature defaults. Your citation rate on ChatGPT and your citation rate on Gemini for the same prompt can differ by 40 percentage points or more. A tool that monitors only one engine is reporting a fraction of your actual exposure. See how Perplexity specifically handles brand citations to understand how different the behavior can be across platforms.
What Reliable Methodology Actually Requires
If non-determinism is the problem, statistical sampling is the solution. Here's what correct methodology looks like:
Multiple runs per prompt. Instead of running each prompt once, a reliable system runs it many times and aggregates the results. If your brand appears in 7 out of 20 runs, your citation rate for that prompt is approximately 35%. That's a real number you can track over time. A single yes/no is not.
Trend tracking, not snapshots. Because citation rates fluctuate, the meaningful signal is direction of change, not absolute values. Is your 35% citation rate on that prompt moving up or down over weeks? That tells you whether your content strategy is working. A static snapshot taken once tells you nothing about trend.
Broad prompt coverage. You need to track visibility across the full range of prompts that represent how your buyers actually search. High-intent comparison prompts, category-level awareness prompts, feature-specific prompts, problem-framing prompts. The more coverage, the more accurate the picture of where you're winning and losing. This is the foundation of a real AI brand monitoring strategy.
Multi-engine sampling. Reliable monitoring covers multiple AI engines simultaneously, not just the most popular one. ChatGPT, Gemini, Grok, and others each behave differently, and buyers use all of them.
Citation source tracking. Beyond whether your brand is mentioned, reliable monitoring captures which URLs the AI engine cites as supporting sources. This is where actionable strategy comes from. If a competitor is getting cited because of one specific page on their site, you can see that and respond.
The Numbers That Actually Matter
When you have correct methodology in place, the useful metrics look like this:
- Citation rate per prompt: What percentage of runs of this specific prompt result in a brand mention? (e.g., 45% for "best CRM for startups")
- Citation rate by engine: How does your rate vary across ChatGPT vs. Gemini vs. Grok for the same prompt?
- Citation rate vs. competitors: When your brand appears at 45%, what are your top competitors at?
- Week-over-week trend: Is your overall citation rate across tracked prompts moving up or down?
- Citation source domains: Which external URLs are being cited alongside or instead of your brand?
These numbers have real business meaning. A 10-point increase in citation rate on high-intent prompts, sustained over four weeks, is a genuine signal that content investment is working. A single mention in one run of one prompt is noise.
Where Confidence Intervals Come In
If you're statistically inclined, you can push further. With enough runs per prompt, you can calculate confidence intervals around your citation rate estimates. Run a prompt 50 times and observe 20 mentions: your 95% confidence interval for the true rate is roughly 27% to 47%.
This matters when you're trying to detect real change versus normal variance. If last month your citation rate was 35% and this month it's 38%, that might be noise. If it moved from 35% to 58%, that's almost certainly a real shift. The only way to tell is with enough samples to have statistical confidence in your estimates.
Most monitoring tools don't give you this. They give you a single number and imply it's precise when it isn't.
How BabyPenguin Handles This
BabyPenguin was built with the non-determinism problem as a first-order constraint, not an afterthought. The platform samples each tracked prompt across multiple runs and engines, aggregates the results, and shows you citation rates rather than binary presence/absence.
You see trend lines, not snapshots. You see your citation rate on specific prompts alongside your competitors' rates. You see which domains are being cited as sources. And you see all of this across ChatGPT, Gemini, Grok, and more, not just one platform.
This is the difference between monitoring that actually informs decisions and monitoring that just gives you something to put in a report. Understanding how to systematically increase your brand mentions starts with having data you can trust.
The Honest Bottom Line
LLM brand citation tracking can be reliable. It requires the right methodology: sampling across multiple runs, tracking trends over time, covering multiple engines, and monitoring a broad set of prompts rather than a handful of generic ones.
Without those properties, you're measuring noise and calling it signal. That's worse than having no data, because it creates false confidence.
Before trusting any monitoring tool, ask specifically how it handles non-determinism. If the answer is vague, or if they haven't thought about the question, the data they're selling you is not reliable.